Enterprise Container Platform Reference Model
1.1 The Enterprise Container Platform Problem
As organisations scale beyond a few homogenous clusters, operational complexity grows quickly across different container runtimes running on-premises, in the cloud and at the edge, with different configurations and characteristics across production clusters, development environments and single-node edge devices.
As a result, operating container infrastructure is non-trivial. Operations become fragile, maintaining consistency and control is hard.
- Manual cluster management causes configuration drift; clusters diverge over time without clear visibility into what changed and why.
- Updating clusters or their configuration is a lengthy, manual task with many exceptions and unique steps for each cluster.
- Access control is inconsistent or overly permissive, not every environment is tied to the corporate identity provider.
- Tooling accumulates: every team has their own tools and ways of work.
- Inconsistent application deployments and pipelines leading to bespoke update cycles and availability issues.
These are the operational realities of a complex landscape across technologies and heterogeneous environments.
Kubernetes has become the dominant substrate for enterprise container workloads. Yet organisations repeatedly discover that Kubernetes is not, by itself, a platform. It is an engine — powerful and flexible, but deliberately unopinionated about the operational, governance, and integration layers that enterprise environments require.
The gap between raw Kubernetes capability and enterprise operational requirements is substantial. A cluster that runs workloads successfully in isolation becomes a liability at scale when it lacks centralised identity enforcement, consistent policy application, auditable change management, and integration with the broader enterprise tooling landscape. Organisations that treat the cluster as the platform typically encounter a predictable set of failure modes: configuration drift between environments, inconsistent security posture across teams, operational knowledge concentrated in a small number of specialists, and growing complexity that erodes confidence and slows delivery.
The human cost of this pattern is significant. Platform engineers operating without systematic governance tooling spend disproportionate time on reactive work — chasing drift, untangling access issues, responding to incidents that consistent policy would have prevented. Specialist dependency becomes a single point of failure. As Kubernetes adoption grows, the operational burden scales faster than team capacity.
Widespread and mature adoption of any technology within the enterprise is subject to common guardrails: visibility and insights, security, cost control, governance, and compliance. Kubernetes-based container environments are no exception and must be managed systematically under architecture. The key drivers this reference architecture addresses are:
- Operational control that degrades as Kubernetes adoption grows without a central management capability
- The need for standardised platform operations and a single operating model across heterogeneous environments
- Multi-cluster sprawl across cloud, on-premises, and edge, with no consistent control surface
- Configuration drift across environments and absence of consistency at fleet scale
- Lack of centralised visibility and control across the container estate
- Governance and compliance requirements that cannot be met through manual or per-cluster processes
- Security and auditability mandates that demand a unified control and audit function
- Growth in edge and distributed compute that introduces new operational complexity and connectivity constraints
- Technology complexity pressing on thinly-spread, multi-disciplinary operations teams
Organisations rely on Kubernetes more than ever — it has become the standard foundation not only for internally developed applications, but also for software delivered by third-party vendors. Yet its technical depth and fragmented tooling landscape pull operational teams into low-level technological concerns rather than business outcomes. Short-term workarounds and ad-hoc fixes become necessary to overcome technological hurdles, but over time they lead to loss of control, instability, outages, configuration drift, and growing compliance and security exposure. The result is predictable: stalled modernization projects, lagging adoption of new technologies, fragile platforms, operational burnout, and rising risk.
The moment an organisation has more than one container environment, the questions operators are trying to answer shift from orchestration to governance:
- How do we apply consistent access control everywhere?
- How do we deploy applications safely without giving everyone cluster-admin?
- How do we see what is running, who changed it, and whether it drifted?
- How do we operate all of this without doubling the size of the team?
These are the questions this reference architecture answers. This is the enterprise container management problem.
1.2 The Operator Control Plane Concept
The response to the enterprise container platform problem is not to replace Kubernetes — it is to govern it. An operator control plane is the management and governance capability that sits above Kubernetes and transforms raw cluster infrastructure into a controllable, auditable, enterprise-grade platform.
The control plane separates two concerns that are frequently conflated. Infrastructure — the clusters, nodes, networking, and storage — is the engine. Control — RBAC, policy enforcement, GitOps reconciliation, audit logging, fleet management, and identity integration — is what makes the engine governable. Without this separation, every governance concern must be solved individually per cluster, producing the drift and inconsistency described in section 1.1. These are control plane questions, not orchestration questions. Kubernetes is very good at orchestrating containers inside a single environment; it was not designed to let operators manage a fleet. That is the gap the operator control plane fills.
The operator control plane is the missing piece in most enterprise Kubernetes deployments. Developer-first platforms address a different problem: they curate the full stack and abstract infrastructure from application developers, which provides value in engineering-led organisations where the goal is maximising developer autonomy. The operator control plane serves a different organisational profile — enterprises that need systematic governance, operational consistency, and auditability across a diverse and potentially large fleet, without requiring every person who interacts with the platform to be a Kubernetes specialist.
An operator control plane has four defining characteristics. It understands fleets — policies, access rules, and deployment patterns apply consistently across all environments, not one cluster at a time. It is designed for delegation — teams can deploy and manage what they are responsible for without global administrative access, with guardrails built into the workflow rather than bolted on afterward. It reduces cognitive load — operators work from a consistent operational surface regardless of whether the underlying environment is cloud Kubernetes, on-premises Kubernetes, or standalone Docker. And it acknowledges constraints — edge, air-gapped, and intermittently connected environments are first-class citizens, not afterthoughts.
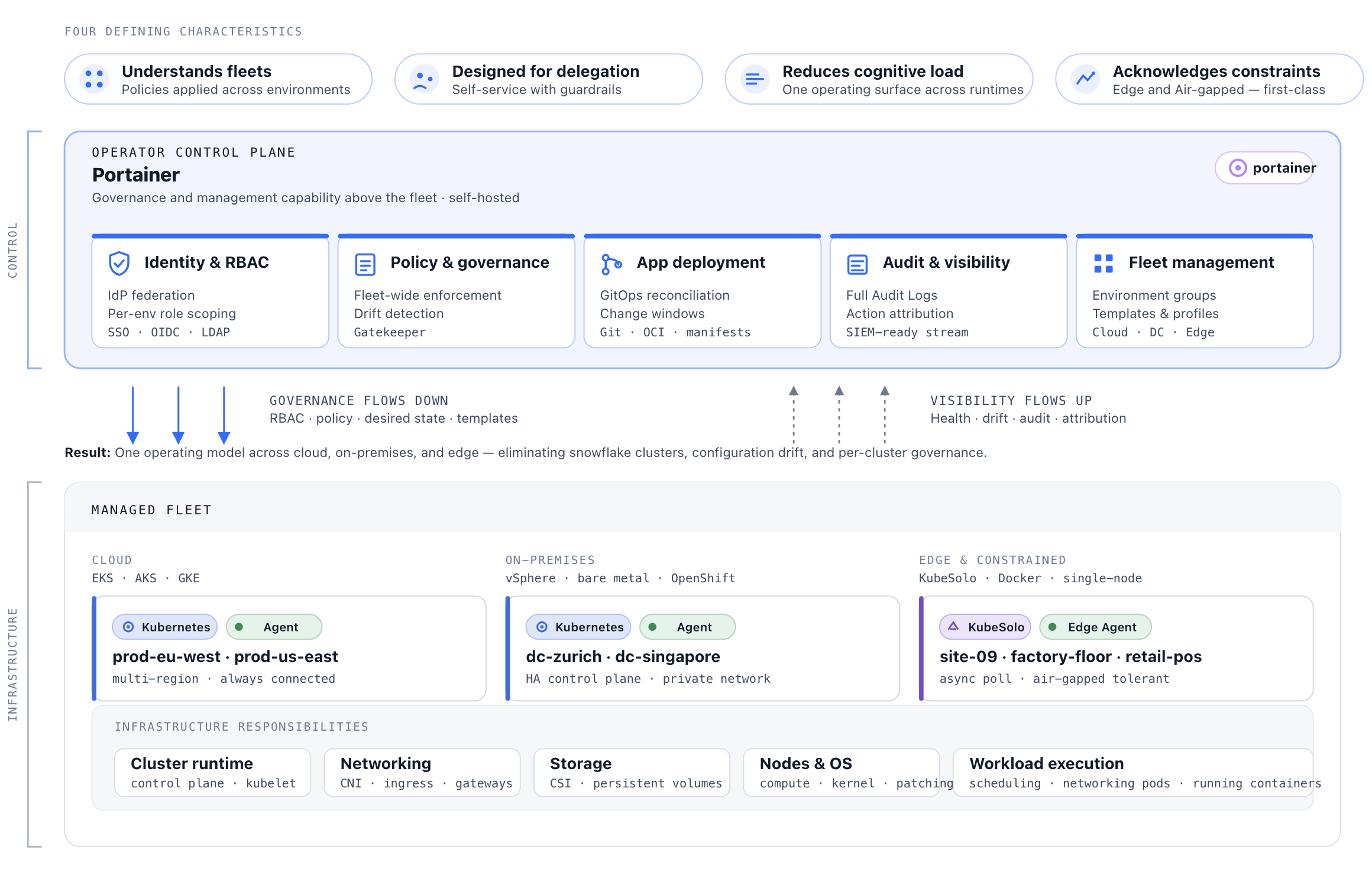
Portainer is an enterprise container management control plane — not a simple UI overlay, but a governed control plane that enforces access, policy, and visibility across the full container estate. It sits above Kubernetes, Docker, and container runtimes to provide a consistent, centralised operational model across all environments — cloud, on-premises, and edge. Instead of treating each cluster as a unique system, Portainer enables organisations to manage container platforms as a fleet , governed by shared policies and operational standards. Portainer centralises identity and access control, governance and policy enforcement, application deployment workflows, auditability and operational visibility, and multi-cluster and multi-environment management. By doing so, it eliminates “snowflake” clusters — environments that have accumulated unique configurations, undocumented changes, and individual dependencies that make them impossible to safely replicate or modify — reduces operational toil, and ensures environments remain secure, compliant, and reliable as they scale. Portainer is designed to be operated by enterprise IT teams, not just Kubernetes specialists.
1.3 The Seven-Layer Enterprise Stack
A complete enterprise container platform spans seven distinct layers. Each layer introduces operational responsibility, integration cost, and risk. Understanding which layer a given decision addresses is essential for avoiding confusion, overlap, and gaps across the platform. The seven layers are organised into three deployment contexts that reflect where each layer runs and how the components connect.
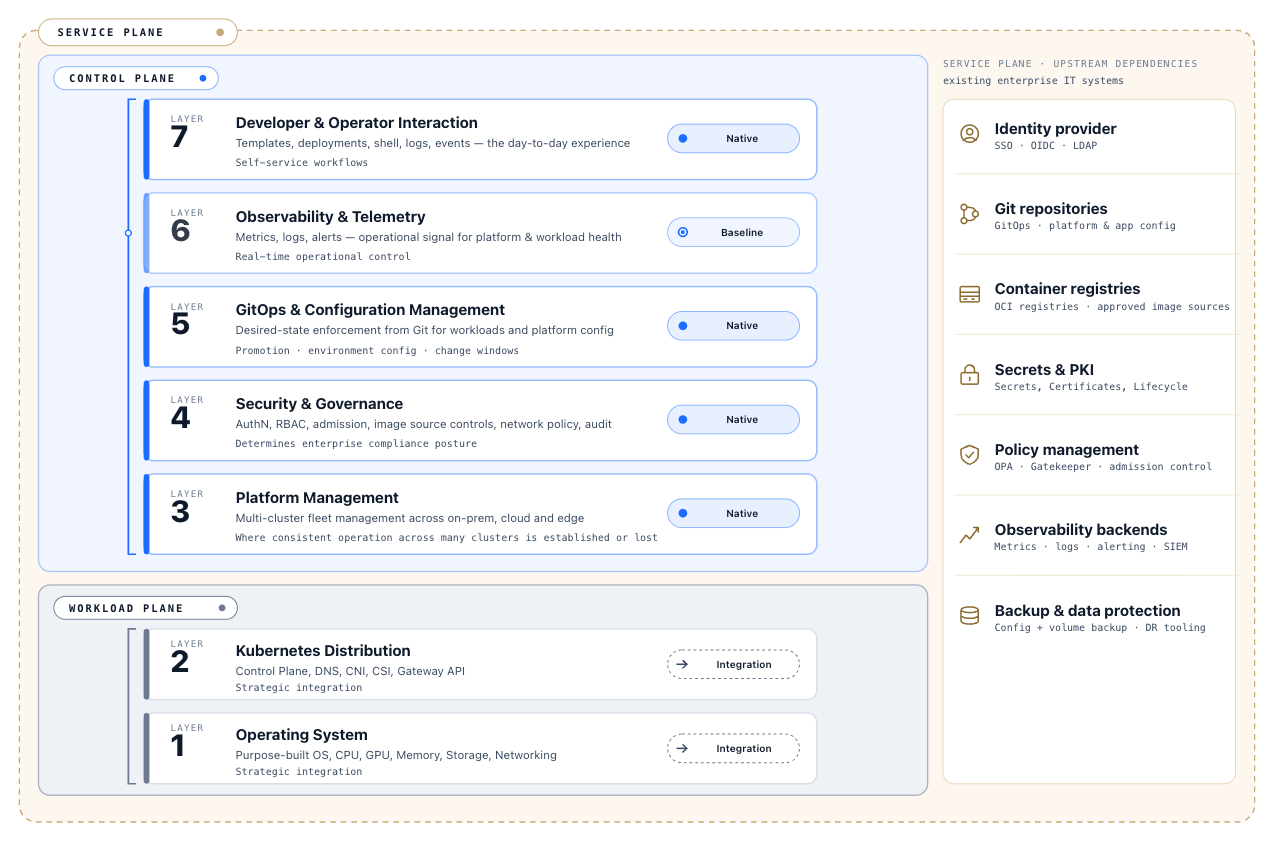
Cluster Infrastructure (Layers 1–2)
These layers run on every managed cluster node and form the execution environment for all workloads. Layers 1 and 2 are supported through strategic integrations with the provisioning ecosystem rather than by duplicating existing solutions inside of Portainer.
Layer 1 — Operating System. The foundation on which every node runs. Key decisions include immutable vs. general-purpose OS, secure boot, disk encryption, patching strategy, and API-driven vs. SSH-based configuration. The OS determines the security posture and operational consistency of the node fleet.
Layer 2 — Kubernetes Distribution. The certified Kubernetes distribution running on the OS. Key decisions include distribution selection, cluster control plane high availability, CNI, CSI, and ingress. The distribution determines the API surface available to all layers above. Every managed cluster runs a Portainer Agent that connects it to the Portainer Server.
Cluster infrastructure is operationally self-sufficient. If Platform Governance is temporarily unavailable, environments continue running on their last applied state without interruption.
Platform Governance (Layers 3–7)
These layers are owned and operated by the Portainer Server — a self-hosted management instance running on a dedicated cluster within the organisation’s own infrastructure, with no dependency on Portainer-operated cloud services.
Layer 3 — Platform Management. The fleet control layer: multi-cluster management, cluster templates, environment grouping, agent management, and centralised configuration. This is where consistent operation across many clusters is established or lost.
Layer 4 — Security and Governance. Centralised authentication, RBAC, policy enforcement via admission control, image source controls, network policy, and audit logging. This layer determines whether the platform can satisfy enterprise security and compliance requirements.
Layer 5 — GitOps and Configuration Management. Desired-state enforcement for workloads and platform configuration, sourced from Git. Promotion workflows, environment-specific configuration, and change window controls live at this layer.
Layer 6 — Observability and Telemetry. Metrics collection, log aggregation, and alerting. Collection runs on every cluster; aggregation and analysis run on dedicated central infrastructure. This layer provides the operational signal needed to understand platform and workload health. Portainer provides baseline observability natively; full-stack observability pipelines are covered in Chapters 9–11.
Layer 7 — Developer and Operator Interaction. Self-service interfaces, application templates, deployment workflows, shell access, log viewing, and event inspection. This layer determines the day-to-day experience of the teams using the platform.
Across these layers, the Portainer Server provides:
- Centralised fleet management — unified visibility and control over all managed environments, regardless of type, location, or connectivity model
- Identity integration and RBAC — enterprise directory integration, team-based role assignment, and per-environment access scoping
- GitOps orchestration — centralised desired-state enforcement sourced from Git repositories, with change window controls and environment promotion workflows
- Policy distribution and enforcement — propagation of governance policies to all managed environments, with fleet-wide drift detection and remediation
- Operator portal — the web interface and API through which platform engineers, operators, and developers interact with the fleet: deployments, logs, terminal access, events, templates, and resource inspection
- Audit trail — a complete, tamper-evident record of all user actions and system events, forming the primary compliance audit source for the platform
Portainer’s coverage is intentionally strongest in Layers 3, 4, 5, and 7 — where operator control and governance deliver the highest return. Deployment, HA, sizing, and lifecycle management of the Portainer Server are covered in Chapter 2.
1.4 Portainer in the Enterprise Landscape
With Portainer, organisations adopt a unified Kubernetes management platform that provides a consistent, governed, and scalable foundation for container operations across data centre, cloud, remote site, and far edge environments.
As Kubernetes usage grows, the need for a centralised Control Plane becomes critical. Fragmented cluster deployments, inconsistent security controls, and varied team practices significantly increase operational risk and reduce an organisation's ability to run Kubernetes in a safe and repeatable manner. Portainer addresses this by sitting between users and the platform — abstracting the complexity of individual cluster operations while preserving full governance control at the fleet level.
Portainer is positioned as a Kubernetes management platform, an operational governance capability, and a fleet management control plane. This distinguishes it from three common alternatives:
Native CLI operations (kubectl, helm) provide direct cluster access but offer no governance capability, no management-level audit trail, no fleet-wide consistency, and no access delegation model suitable for enterprise teams. They are appropriate for individual engineers but do not scale to organisational governance requirements.
Cloud-provider consoles provide visibility and management for clusters within a single cloud provider's estate but do not extend to on-premises, edge, or multi-cloud environments. They also do not provide the unified RBAC, policy, and GitOps model required for consistent fleet governance across a heterogeneous estate.
GitOps-only approaches (Argo CD, Flux) address configuration management and desired-state reconciliation within clusters but do not provide centralised RBAC, fleet management, identity integration, or the operational console capabilities required for day-to-day platform operations.
Bespoke CNCF platform builds — assembling a governance stack from open-source CNCF components (Argo CD, Dex, OPA Gatekeeper, Prometheus, Loki, cert-manager, and others) — are technically viable and widely attempted. The appeal is understandable: the components are free, well-documented, and used by sophisticated organisations. The cost that is consistently underestimated is the ongoing operational burden: integration ownership, semi-annual upgrade coordination across the full stack, internal support, and the compounding engineering effort to keep all components current and compatible. This decision is frequently driven by engineering teams who underestimate long-term labour cost; leadership should ensure the ongoing resource commitment is explicitly scoped before committing to the build path. For teams with the engineering capacity and appetite to own a full platform stack indefinitely, a bespoke build is a legitimate choice. For most enterprise IT organisations — where the platform is a means to an end, not a product — it becomes a long-term liability [1].
Portainer provides the integration point that connects these concerns into a single governed operating model. Its key capabilities in the enterprise context are:
- Multi-cluster governance — a single control surface managing environments across cloud, on-premises, and edge
- Role-based access control delegation — enterprise directory integration with fine-grained, per-environment role assignment
- Controlled self-service — teams access what they need within defined boundaries, without requiring administrator involvement for routine operations
- Fleet policy enforcement — governance policies propagated and enforced consistently across all managed environments
- GitOps enablement — centralised, auditable configuration management with change window alignment
- Standardised cluster operations — consistent operational patterns regardless of underlying distribution or cloud provider
- Edge cluster lifecycle management — asynchronous agent operation for remote and disconnected environments
Portainer integrates with upstream enterprise systems (identity providers, Git repositories, container registries, policy stores) and feeds downstream systems (logging platforms, metrics stacks, SIEM). It does not replace these systems — it provides the governance and management function that connects them into a coherent operating model.
Enterprise Integrations
The Portainer platform connects to enterprise systems that both the Portainer Server and managed clusters consume or emit signals to.
| Integration with | Description | Chapter |
|---|---|---|
| Identity Provider | User authentication and RBAC group mapping | Ch. 4 |
| Container Registry | Image governance, supply chain enforcement, and image pull | Ch. 5 |
| Git Repository | GitOps source for cluster configuration and workload deployment | Ch. 6 |
| Policy Management | Admission control policy distribution and enforcement | Ch. 7 |
| Secret Management | Runtime credential delivery to workloads; Portainer credential protection | Ch. 8 |
| Certificate Management | PKI and TLS lifecycle for Portainer Server and workload endpoints | Ch. 2, 3 |
| Logging | Log collection on clusters; central aggregation and operational query | Ch. 9 |
| Metrics | Metrics collection on clusters; central storage, dashboards, and SLO tracking | Ch. 9 |
| Alerting | Alert routing, on-call scheduling, and incident management | Ch. 9 |
| SIEM / SOC | Security event correlation and compliance reporting, fed by Portainer’s audit trail | Ch. 10 |
| Data Protection | Backup for cluster workloads and Portainer Server configuration state | Ch. 2, 11 |
Core Capabilities
Centralised Governance and Control: Define access, roles, and permissions once and apply them everywhere. Enforce consistent policies across clusters and environments. Maintain continuous alignment with organisational standards.
Secure, Auditable Operations: Full audit logging of configuration changes and deployments. Clear accountability for access and actions. Built-in support for compliance and security reviews.
Cost-Effective Multi-Cluster Management: Manage many clusters without linear increases in effort. Reduce tooling sprawl by consolidating operational functions. Prevent configuration drift that leads to outages and rework.
Controlled Self-Service: Separate infrastructure governance from application delivery. Platform teams govern infrastructure without blocking productivity. Git-based automation for application teams enables controlled, consistent, repeatable application delivery across clusters.
Broad Environment Support: Kubernetes distribution-agnostic; works across Docker, Podman, and single-node Kubernetes; designed for data centre, cloud, air-gapped, and edge environments.
When Organisations Adopt Portainer
Portainer is specifically designed for enterprise IT organisations where:
- IT is primarily a cost centre, with pressure to reduce operational overhead
- Stability, security, and predictability are paramount
- Teams are composed largely of generalists, not deep Kubernetes specialists
- Kubernetes adoption is driven by operational necessity, not experimentation
- Platforms must operate with constraints — including strict compliance and security regulations, or bandwidth and networking constraints in edge, air-gapped, or low-bandwidth environments
Portainer enables these organisations to adopt containers responsibly — without building bespoke platforms or scaling headcount linearly. Within this profile, organisations reach for Portainer when container platforms become operationally significant. Common triggers for adoption include:
Kubernetes becomes business-critical: When clusters support production workloads, informal practices no longer suffice. Portainer introduces operational discipline and structure to scale.
Multi-cluster sprawl: As clusters multiply across teams and locations, Portainer provides a way to manage them safely as a fleet, allowing teams to own their environments while staying within governance boundaries.
Vendor-driven container adoption: When software vendors mandate containers, Portainer enables secure, governed consumption without redesigning IT operations.
Teams manage tools, not deliver outcomes: When teams are overloaded with complex toolchains, Portainer reduces operational surface area and cognitive load.
Growing governance and compliance pressure: When audits, security reviews, and regulatory requirements increase, Portainer embeds consistency and governance directly into operations.
Edge and regulated environments: When containers extend beyond the data centre into factories, retail locations, and operational technology contexts, Portainer provides consistent control despite limited local expertise and resource constraints.
Leadership demands predictability: When executives need operational insight, stable costs, and reliability — not heroics — Portainer institutionalises control.
Adoption does not require a platform rebuild or rip-and-replace of existing workflows. Portainer can be introduced incrementally, coexist with current CI/CD and GitOps processes, and be applied where it delivers the most immediate value. Over time, it allows teams to standardise the majority of operational tasks while leaving room for advanced users to work directly with underlying platforms when needed.
1.5 Architecture Principles
The following principles are the governing rules of this reference architecture. They represent long-lived design truths and should not be altered without reassessing the broader platform design. They apply equally to new deployments and to the evolution of existing platforms.
Non-functional Principles
Before assessing features, assess operational sustainability. A tool that cannot be maintained, supported, or scaled within your team’s capability is a liability regardless of its technical merits. The nine NFRs that matter most in enterprise platform contexts:
- Supportability — Is there a vendor with real SLAs, or a talent market you can access? Tools that depend on unicorn engineers or heroic self-support are risks, not assets.
- Maintainability — Can your team realistically keep pace with the release cadence, upgrades, and patches? Falling behind on a critical infrastructure component introduces compounding risk.
- Survivability — What is the recovery plan if the vendor disappears or the open-source community fragments? Dependence on fragile ecosystems is a risk that is consistently underestimated.
- Scalability — Can you start at your current scale and grow, or does the tool demand enterprise-scale rollout from day one? Tools that only work at scale are traps.
- Availability — Does the solution align with the SLA the business requires? Best-effort promises are not sufficient for regulated or business-critical platforms.
- Resiliency — When something fails, what is the recovery path and how long does it take? If the answer is “slowly” or “manually,” the risk profile is already clear.
- Usability — Does the user experience match your team’s skill profile? Tools that require months of specialist training are not accelerators — they are bottlenecks.
- Security — Does it align with your enterprise security posture without extensive bolt-ons after deployment? Security retrofitting is more expensive than security built in.
- Deployability — Can it be deployed and operated securely by your team, or does it require specialist knowledge to configure correctly? There is a significant gap between “it runs” and “it is production ready.”
The failure mode this framework guards against is conference-driven platform design : adopting tools and patterns not because they solve a current problem within your constraints, but because they are fashionable, because peers use them, or because vendors presented compelling demonstrations. This is how enterprises assemble stacks of tools that nobody fully understands, monitoring systems so complex they need their own monitoring, and pipelines bloated with integrations that were never evaluated against the questions above. Resist it. Every tool in the platform stack should be able to answer all three pillars. If it cannot, it has no place in a production platform.
Platform Principles
Declarative production configuration. All production workloads and cluster configuration must be applied through a declarative model, sourced from a GitOps engine using Git or OCI registries as the source of truth. This ensures production behaves predictably, remains fully auditable, and configurations are reproducible. See Chapters 5 and 6.
Single Control Plane. A single Control Plane governs configuration, security, and operations across all clusters. Fragmentation of control must be avoided unless explicitly required for regulatory or organisational separation. Where segmented planes are required, both must follow the same governance and declarative standards.
Cluster immutability through profiles. Clusters must be created from predefined profiles that enforce consistent configuration, security, and operational patterns across the fleet. Clusters that diverge from approved profiles introduce operational risk and compliance exposure. See Chapter 3, section 3.7.
Guardrails and Golden Paths. The platform provides intuitive, safe workflows for workload delivery, supported by policy guardrails that prevent unsafe or non-compliant configurations without constraining legitimate operations. Operator freedom is bounded, not eliminated. See Chapters 4 and 7.
Plane independence and connectivity resilience. The platform is designed for operational independence between planes. The Workload Plane continues running autonomously when the Control Plane is temporarily unavailable — workload continuity must never depend on Control Plane availability. The Edge Agent model extends this principle to intermittently connected environments: edge clusters operate normally and reconcile asynchronously when connectivity is restored. Control Plane availability and workload availability are independent concerns by design. See Chapter 2.
Security Principles
Identity-driven authorisation. Access must always be derived from the enterprise identity provider — not only for Portainer, but across entire container management platform, including logs, metrics, etc. The enterprise IdP is the single canonical source of access truth; any component that cannot federate to it becomes an access island requiring separate lifecycle management. Access privileges map to persona-based roles and are consistent across all clusters. Short-lived, just-in-time credentials are preferred over long-lived tokens or static kubeconfigs. See Chapters 4 and 8.
Least Privilege by Default. All access begins at minimum permission levels. Users, service accounts, and platform components receive only the permissions required for their defined function. Elevated access requires explicit grant, not default inheritance.
No direct cluster API access. Under normal operations, users must not interact directly with cluster APIs. The Control Plane is the authorised access surface for all cluster interactions — it validates identity, confirms authorisation scope, enforces policy, and records every action before routing it to the target environment. Direct kubectl access to production clusters must be eliminated as a routine operational path and reserved for documented break-glass scenarios . This is the architectural basis for Portainer’s access control and audit guarantees. See Chapter 4.
Centrally defined security baseline. Security posture is defined once as an organisation-wide baseline and propagated consistently to all clusters. Environment-specific overlays may apply additional controls for cloud, data centre, or edge environments, but cannot weaken the baseline.
Auditability and transparency. Every change — whether configuration or operational — must be independently auditable. No undocumented or manual configuration pathways exist in production. The audit trail must be forwarded to a system outside the platform itself. See Chapters 2 and 10.
Controls are additive, not substitutive. Platform security controls operate as a defence-in-depth stack — each control adds protection independently rather than replacing another. Portainer’s governance controls are not a substitute for admission controller enforcement; admission control is not a substitute for runtime policy. A failure or deliberate bypass of one control does not negate the protections of the others. Security posture is assessed across all active controls collectively. See Chapter 7.
Secrets never touch Git. No secret value — password, token, certificate, or any sensitive material — may appear in a Git repository in any form, whether plaintext, base64-encoded, or any reversible encoding. GitOps pipelines hold only references to secrets (ExternalSecret CRDs, SealedSecret ciphertext) — never secret material itself. This constraint applies to Portainer GitOps stack definitions, application manifests, and Helm values alike. A committed credential creates a permanent disclosure risk for the lifetime of the repository, regardless of subsequent rotation. See Chapter 8.
Operational Principles
Namespace isolation as the tenancy construct. Workloads are deployed into purpose-defined namespaces with standard resource quotas, limit ranges, and network policies. Only platform components run in system namespaces. See Chapter 3, section 3.8.
Automation by default. Manual intervention is the exception. Automated workflows and declarative state reconciliation underpin administrator-driven workflows and developer self-service. Routine tasks do not require direct cluster API access or per-cluster manual configuration.
Out-of-band and machine-readable alerting. Platform alerts must reach on-call engineers through channels that remain functional when the platform interface is unavailable. Alerts must be emitted in machine-readable formats suitable for aggregation into enterprise monitoring systems. See Chapter 9, section 9.5.
1.6 Business Outcomes
A governed enterprise container platform, operated through a centralised control plane, delivers measurable business outcomes across seven dimensions:
Predictable operational cost. The largest cost driver in enterprise Kubernetes adoption is not infrastructure or licensing — it is the people required to design, build, and run the platform. A single-cluster environment incurs approximately $92,000 in first-year labour and $36,000/year ongoing; at enterprise scale, annual run costs routinely exceed $1 million before any infrastructure spend is counted [1]. Centralised platform management reduces engineering burden by 40–60% compared to bespoke CNCF builds [1], through consolidation of operational functions, elimination of tooling sprawl, and reduction of manual effort across teams and clusters.
Reduced operational risk. Centralised governance, consistent configuration, and full auditability reduce the probability and blast radius of misconfiguration incidents. When every change flows through a single governed path, drift and undocumented change are structurally prevented rather than reactively discovered.
Improved reliability and stability. Consistent fleet-wide configuration and policy enforcement eliminate the conditions that produce outages. Environments that diverge from a known baseline are a persistent source of instability; environments governed from a unified control surface are not.
Sustainable scaling. Container platforms can be expanded without proportional increases in headcount or Kubernetes expertise. Operations scale through governance tooling, not hiring. As the fleet grows, the team does not need to grow at the same rate — that is the difference between containers remaining an enabler and becoming a tax on the organisation.
Security and compliance by design. Governance embedded into daily operations eliminates the gap between security posture on paper and security posture in practice. Audit trails, access control, and policy enforcement become structural features of the platform — not additions imposed during audit cycles.
Organisational resilience. Platforms that depend on individual heroics or tribal knowledge concentrated in a small number of specialists are fragile. Systematic governance distributes operational knowledge and makes procedures transferable — the platform continues operating when individuals leave, rotate, or are unavailable.
Operational reach across constrained environments. Regulated, air-gapped, low-bandwidth, low-resource, single-node, and edge environments require consistent governance regardless of connectivity or resource profile. A platform designed for operational heterogeneity governs these environments on the same model as data centre and cloud clusters — not as afterthoughts.
Portainer is the implementation of this governance model — the operator control plane that makes these outcomes achievable without requiring the organisation to build and maintain a bespoke governance stack.
[1] Portainer, "The True Cost of Kubernetes Platform Adoption" . Labor cost benchmarks derived from U.S. Bureau of Labor Statistics and Levels.fyi . Managed Kubernetes labor reduction estimates referenced from Datadog, "State of Kubernetes," 2023 .